GAN的开山之作:Generative Adversarial Nets
问题
深度学习在判别模型上取得了显著的成功,特别是那种高维、丰富的感官输入映射到一个类标签上的场景,但是在生成模型中成果较小,主要是因为以下两个问题:
- 在极大似然估计和相关策略中出现的许多难以处理的概率计算的近似性
- 难以在生成环境中利用分段线性单元的优点
背景知识:生成模型VS判别模型
判别方法:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。典型的判别模型包括k近邻,感知级,决策树,支持向量机等。
生成方法:由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。基本思想是首先建立样本的联合概率概率密度模型P(X,Y),然后再得到后验概率P(Y|X),再利用它进行分类,就像上面说的那样。
解决方案
为了解决上述问题,我们提出了一种新的生成模型训练框架:对抗网络(adversarial nets)。
adversarial nets是通过对抗过程估计生成模型的框架,同时训练两个模型,一个生成模型G捕获数据分布,一个判别模型D估计样本来自训练数据而不是G的概率。
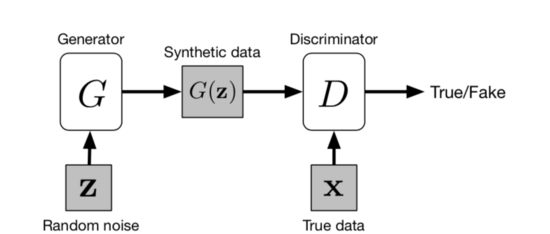
Adversarial nets
Adversarial nets框架最直接的应用就是将生成模型和判别模型都配置成多层感知器。为了在数据上学习生成模型G的分布,我们定义了一个先验的输入噪声变量,然后将噪声变量到数据空间的映射表示为,其中是由多层感知器表示的微分函数。我们还定义了输出单个标量的多层感知器。代表来自训练数据而不是由生成的概率。我们训练判别模型来最大化区分生成模型产生的样本和训练样本,同时训练生成模型来最小化:
D和G玩了一个具有值函数的二人极大极小博弈,D要以最大可能判别出是生成数据,G要生成的数据与真实数据的差距尽可能的小,也就是在循环的过程中同时增强判别器D判别能力与提高生成器G的生成更接近真实数据的能力:
对的理解:
这里的相当于表示真实样本和生成样本的差异程度。
先看。这里的意思是固定生成器G,尽可能地让判别器能够最大化地判别出样本来自于真实数据还是生成的数据。
再将后面部分看成一个整体令,看,这里是在固定判别器D的条件下得到生成器G,这个G要求能够最小化真实样本与生成样本的差异。
通过上述min max的博弈过程,理想情况下会收敛于生成分布拟合于真实分布。
在实际应用中,上面的公式可能无法为提供足够的梯度来学习。在学习的早期,比较弱,可以很有信心地拒绝样本,因为它们与训练数据明显不同。在这种情况下,饱和,与其训练去最小化不如训练去最大化,这一目标函数的结果与动态函数相同,但在学习中提供了更强的学习效果。
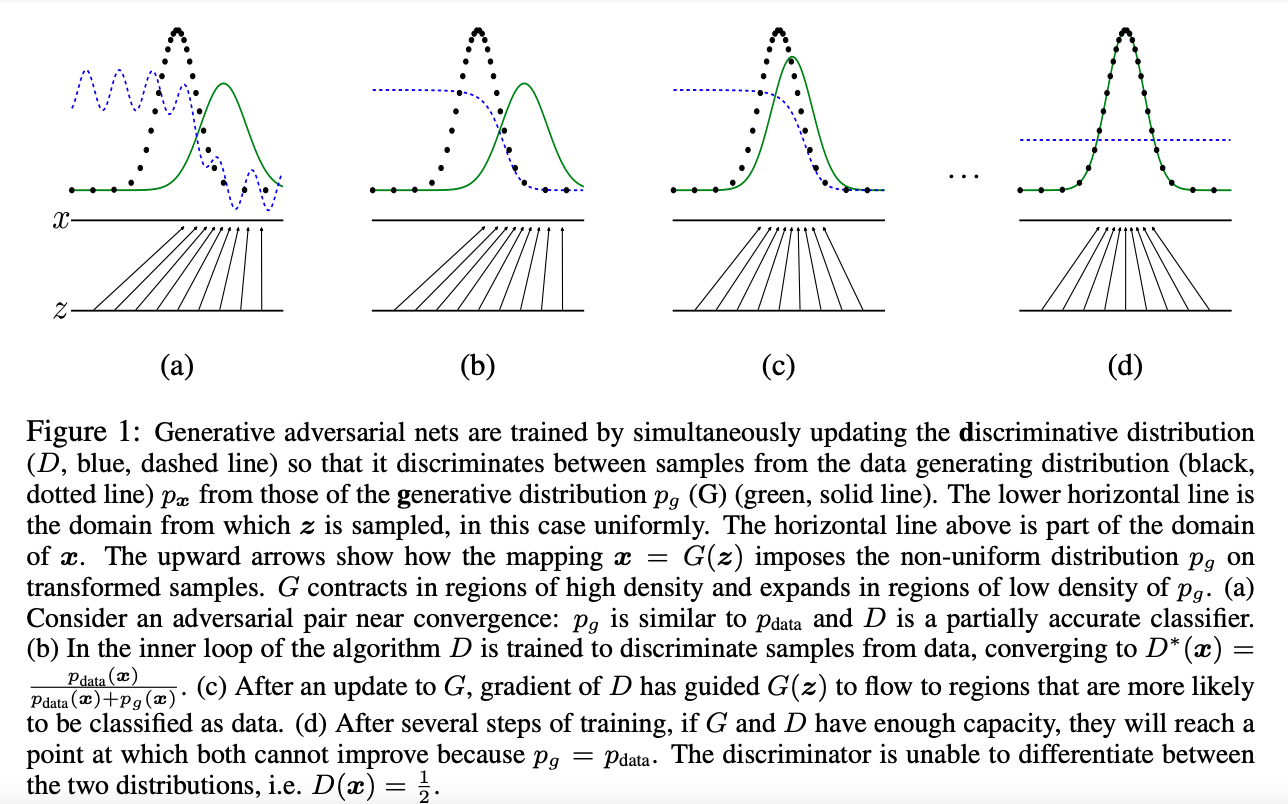
图中的黑色虚线表示真实的样本的分布情况,蓝色虚线表示判别器判别概率的分布情况,绿色实线表示生成样本的分布。Z表示噪声,Z到x表示通过生成器之后的分布的映射情况。
我们的目标是使用生成样本分布(绿色实线)去拟合真实的样本分布(黑色虚线),来达到生成以假乱真样本的目的。可以看到在(a)状态处于最初始的状态的时候,生成器生成的分布和真实分布区别较大,并且判别器判别出样本的概率不是很稳定,因此会先训练判别器来更好地分辨样本。通过多次训练判别器来达到(b)样本状态,此时判别样本区分得非常显著和良好。然后再对生成器进行训练。训练生成器之后达到(c)样本状态,此时生成器分布相比之前,逼近了真实样本分布。经过多次反复训练迭代之后,最终希望能够达到(d)状态,生成样本分布拟合于真实样本分布,并且判别器分辨不出样本是生成的还是真实的(判别概率均为0.5)。也就是说我们这个时候就可以生成出非常真实的样本啦,目的达到。
Theoretical Results
GAN算法流程
- 第一步我们训练,是希望越大越好,所以是加上梯度(ascending)。
- 第二步训练时,越小越好,所以是减去梯度(descending)。
- 整个训练过程交替进行。

-
命题 1:对于固定的G,最优鉴别器D为
-
定理 1:当且仅当pg = pdata时,得到虚拟训练准则C(G)的全局最小值。此时,C(G)等于- log4。
-
命题 2: 当与有足够的容量时, 在给定时,能达到最优值,而也能得到更新,以提升。
对比其他建模方案
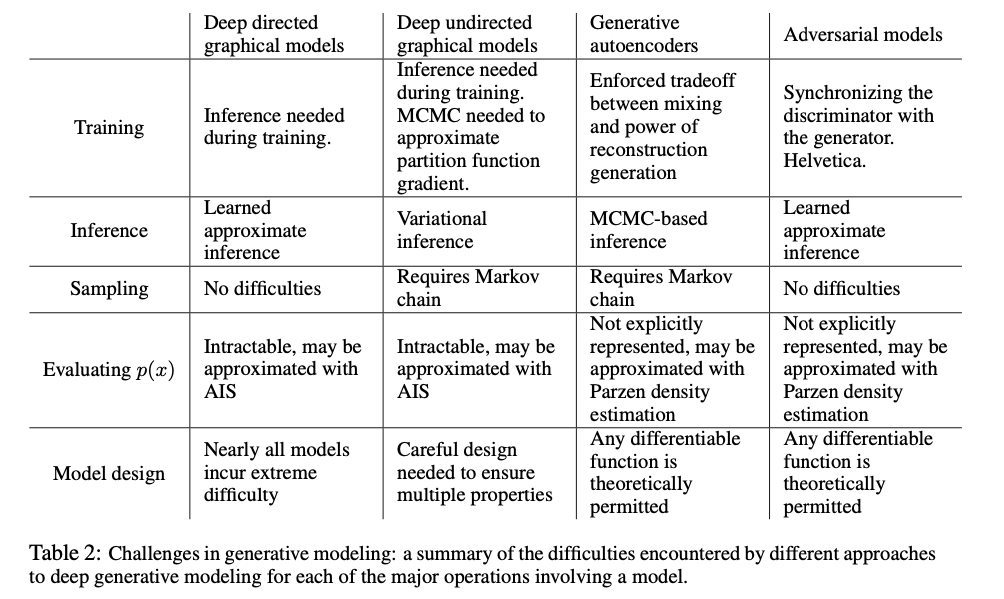
优缺点
优点
- 模型只用到了反向传播,而不需要马尔科夫链
- 训练时不需要对隐变量做推断
- 可以将多种函数合并到模型中
- G的参数更新不是直接来自数据样本,而是使用来自D的反向传播
缺点
- 可解释性差,生成模型的分布没有显式的表达
- 比较难训练,与之间需要很好的同步,例如更新次而更新一次
Conclusion and Future Work
1.CGAN,即根据给定的条件和随机分布,生成特定的数据。
2.通过训练一个给定x,预测z的辅助网络,用于样本之间的相似度检测。
3.可以训练一个shared model,给定任意子条件和随机分布,生成该条件对应的样本。
4.半监督学习:当训练数据有限时,可以使用discriminator的特征或者G网络来提升分类器的性能。
5.在训练的过程中,如果可以确定一个更好的z的分布,则训练速度和模型性能都会大大提升。
参考文献
[1]Generative Adversarial Nets / Ian J. Goodfellow
[2]github源码
[3]通俗理解生成对抗网络GAN / 陈诚 / 知乎
[4]生成模型与判别模型/ zouxy09 / csdn
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!