Google多任务学习模型MMoE
摘要
基于神经网络的多任务学习已成功用于工业界的大规模应用程序中,例如在视频推荐中,只考虑点击转化率时,会倾向推荐包含标题党、擦边海报的视频;只考虑完成度时,会倾向推荐时间比较短的视频等等。而这些倾向都会影响用户体验,并且可能导致业务长期目标的下降。因此,大家开始尝试引入多个相互关联但又不一致的目标来进行综合考虑建模,并且实践表示,多任务学习在推荐系统中能够提升上下文推荐的效果。但是,常用的多任务模型的预测质量通常对任务之间的关系很敏感,因此,研究特定于任务的目标与任务间关系之间的建模折衷至关重要。
Multi-gate Mixture-of-Experts (MMoE)通过在多任务学习中引入Mixture-of-Experts(MoE)层,显式的学习了各个子任务之间关系,同时利用门限网络以优化每个任务。
MMoE的核心思想是集成学习,整个思想范畴在随机森林里面,不过表达方式用了深层Net,这样每个专家可以专注一个方向去学习表达力,门控网络来计算每个专家网络跟目标匹配的权重。
实验表明,当任务相关性较低时,MMoE比基线方法具有更好的效果,并且会带来额外的可训练性好处,具体取决于训练数据和模型初始化中不同程度的随机性。
Motivation
现有方案的弊端
多任务模型通过学习不同任务的联系和差异,可提高每个任务的学习效率和质量。多任务学习的的框架广泛采用shared-bottom的结构,不同任务间共用底部的隐层。但是在实际应用中,多任务学习模型并不总是能在所有任务上都胜过相应的单任务模型,许多基于DNN的多任务学习模型对数据分布差异和任务之间的关系之类的因素都很敏感,任务差异带来的内在冲突实际上会损害至少一部分任务的预测,尤其是在所有任务之间广泛共享模型参数的时候。
我们来看下面这个例子,假设有这样两个相似的任务:猫分类和狗分类。他们通常会有比较接近的底层特征,比如皮毛、颜色等等。如下图所示:
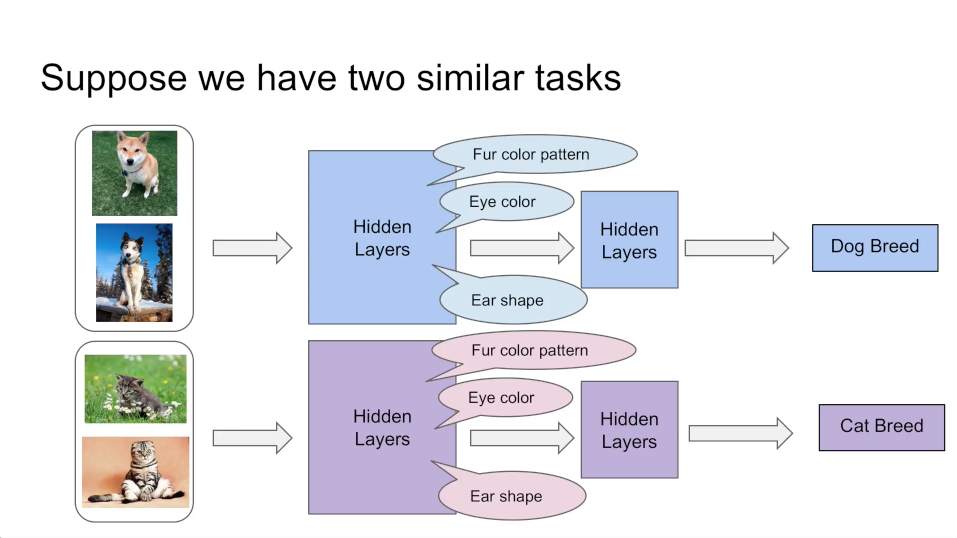
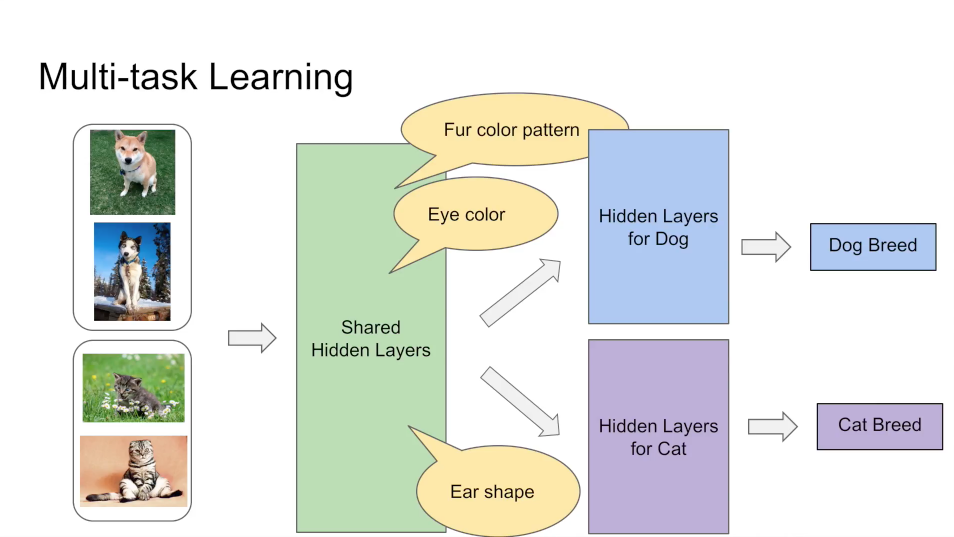
多任务的学习的本质在于共享表示层,并使得任务之间相互影响:
如果我们现在有一个与猫分类和狗分类相关性不是太高的任务,如汽车分类:
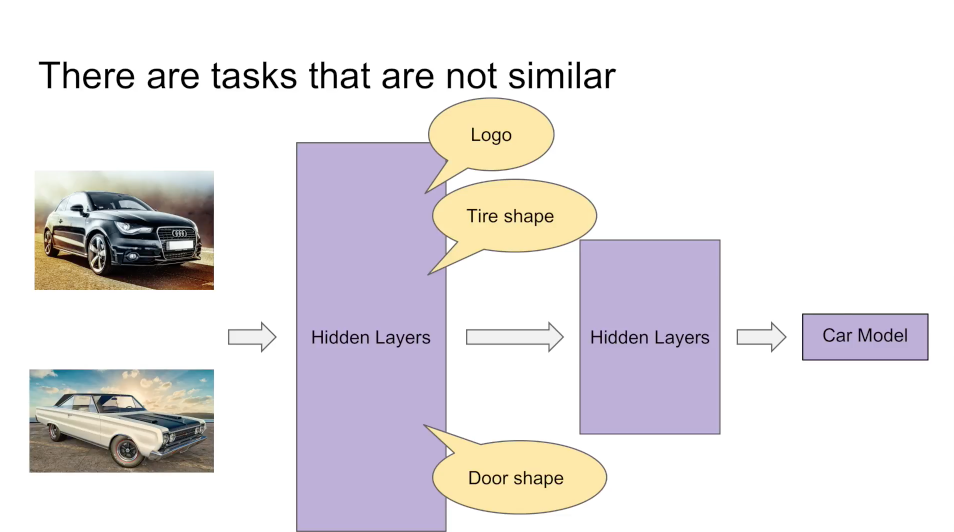
那么我们在用多任务学习时,由于底层表示差异很大,所以共享表示层的效果也就没有那么明显,而且更有可能会出现冲突或者噪声
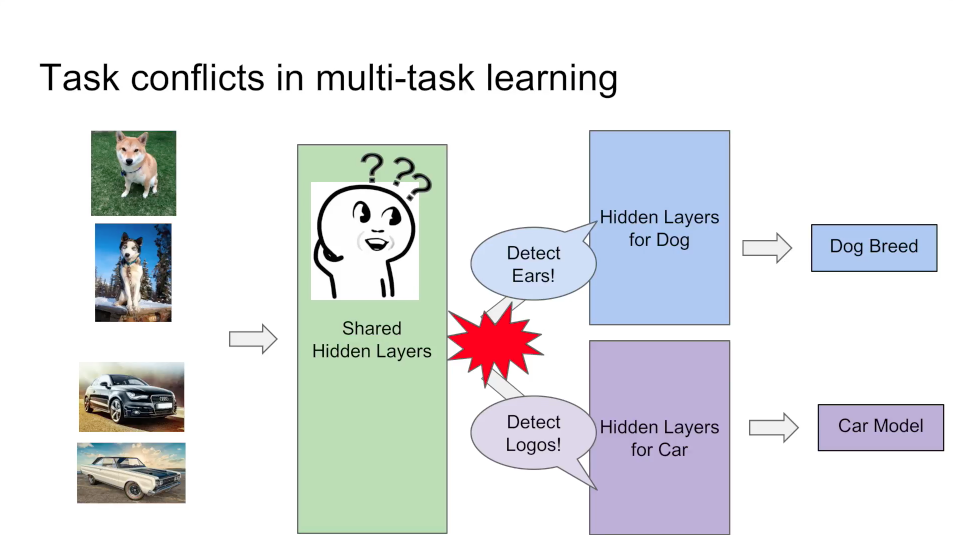
现有的解决方案
- 有一些方案通过假设每个任务的特定数据生成过程,根据假设度量各个任务的差异,然后根据任务差异为后续多任务训练提出指导意见,但是,由于实际应用中数据模式是很复杂的,度量任务之间的差异并且把对应的指导意见利用起来是很困难的。
- 有一些方案可以不依赖任务差异度量的情况下处理多任务学习过程中的差异,但是这些方法通常会为每个模型增加更多模型参数,导致计算开销变大。
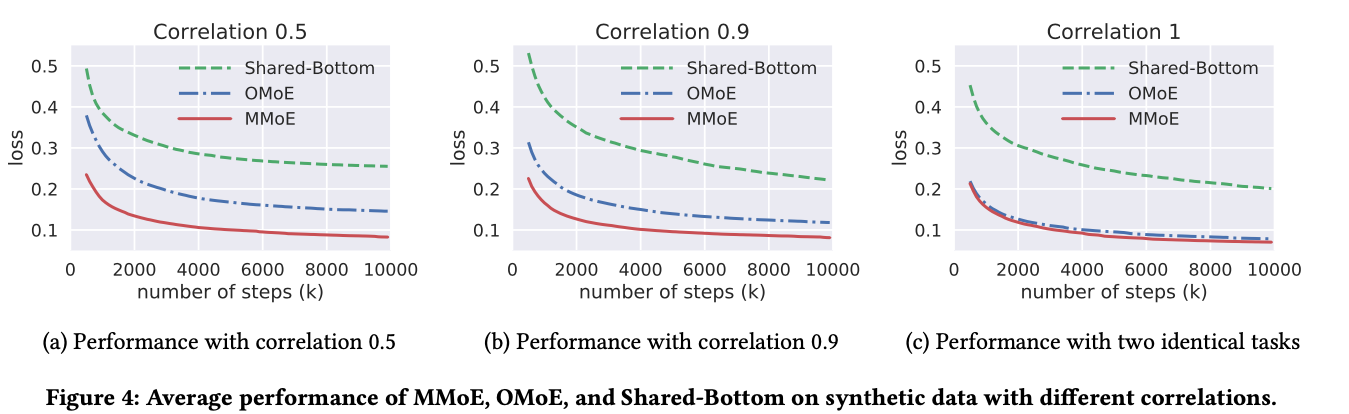
下图给出了相关性不同的数据集上多任务的表现,可以看出相关性越低,多任务学习的效果越差
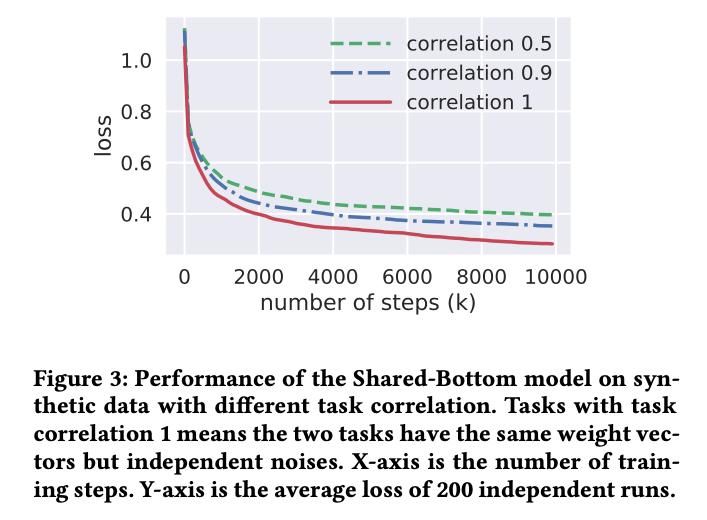
在实际的推荐系统中,点赞、评论或者没有反馈,度量这几个任务之间的相关性也是非常难的。
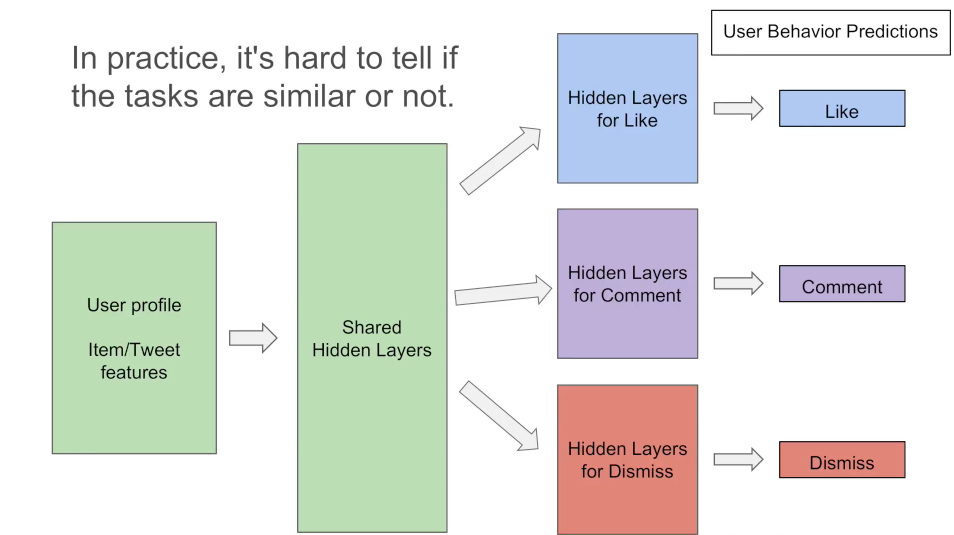
因此,论文中提出了一个Multi-gate Mixture-of-Experts(MMoE)的多任务学习结构。MMoE模型刻画了任务相关性,基于共享表示来学习特定任务的函数,避免了明显增加参数的缺点。
Multi-gate Mixture-of-Experts(MMoE)
We want the model itself to figure out to which extent to share among tasks.
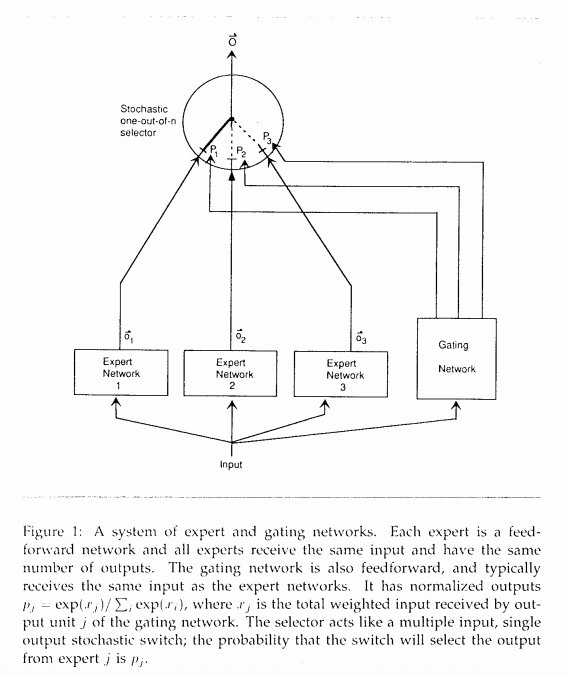
Mixture-of-Experts(MoE)
MoE Model
原始的MoE模型可以形式化为:
- ,其中表示专家的权重,是做过归一化的。g代表一个汇总所有专家结果的门控网络。
- ,表示n个expert networks
- 门控网络根据输入生成n位专家的分布,最终输出为所有专家输出的加权总和。
MoE Layer
- MoE Layer具有与MoE Model相同的结构,但接受前一层的输出作为输入,并输出到连续的层。然后以端到端的方式训练整个模型。
- MoE Layer结构的主要目标是实现条件计算,其中每个实例仅激活部分网络。 对于每个输入示例,模型都可以通过以输入为条件的门控网络来选择专家的子集。
MMoE
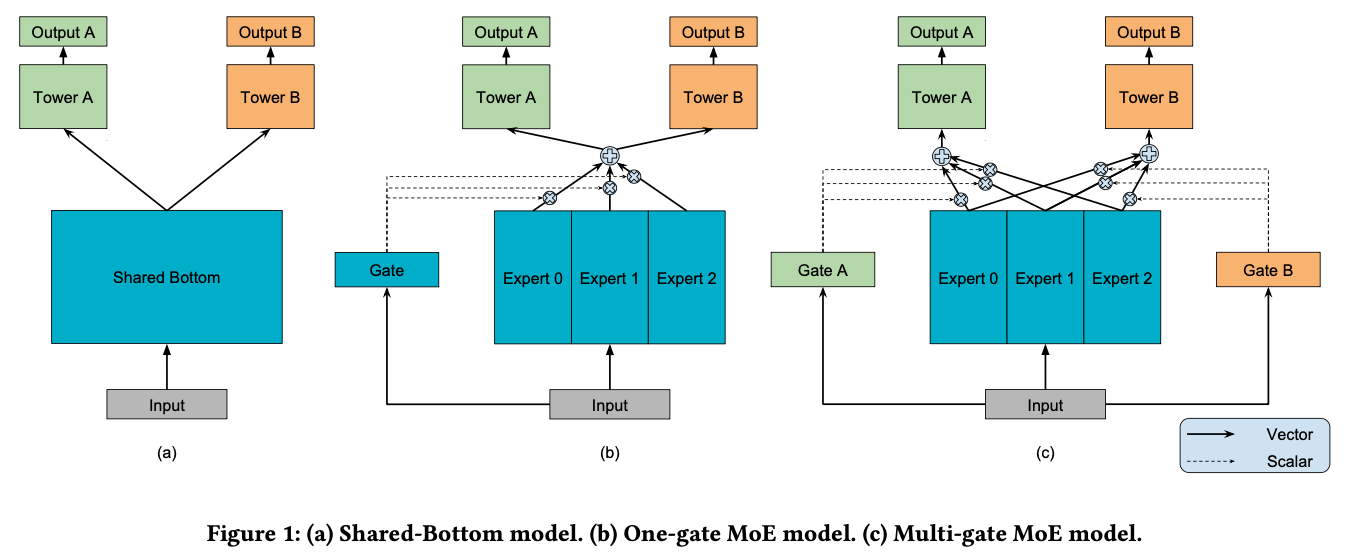
图(a)Shared-Bottom model
共享底层网络在许多多任务学习应用程序中被广泛采用,Shared-Bottom网络位于底部,多个任务共用这一层。往上,每个子任务分别对应一个Tower Network,函数表达式为:
- 表示k个任务
- 表示Shared-Bottom网络
- 表示每个子任务对应的Tower Network
图(b)One-gate MoE model
OMoE是在多任务学习中引入MoE层,将input分别输入给三个Expert(共享子网络),但Expert并不共享参数。同时将input输出给Gate(门限网络),Gate输出每个Expert被选择的概率,然后将三个Expert的输出加权求和,输出给Tower,有点attention的感觉。函数表达式为:
- 表示n个专家网络
OMoE的主要目标是实现条件计算,对于每个数据而言,只有部分网络是活跃的,该模型可以通过限制输入的门控网络来选择专家网络的子集。
图©Multi-gate MoE model
MMoE的目的在于捕获任务差异,而与共享底部多任务模型相比,不需要明显增加更多的模型参数。底部引入MoE层,来显式的对多个任务的关系进行建模,或者理解成学习所有任务的不同方面;再对每个任务学习一个Gate(门限网络),这个Gate可以理解成这个任务在各个方面的特点。函数表达式为:
其中 ,输入就是input feature,输出是所有experts上的权重。
MMoE的每个Gate网络都可以根据不同任务来选择专家网络的子集,所以即使两个任务并不是十分相关,那么经过 Gate 后也可以得到不同的权重系数,此时,MMoE 可以充分利用部分 expert 网络的信息,近似于单个任务;而如果两个任务相关性高,那么Gate的权重分布相差会不大,会类似于一般的多任务学习。
实验结果
我们想了解MMoE模型是否可以更好地处理任务相关性较低的情况,我们对合成数据进行了控制实验以调查此问题。我们改变了数据的任务相关性,并观察了不同模型的行为如何变化。我们还进行了可训练性分析,并表明与基于共享底部的模型相比,基于MoE的模型更易于训练。
Performance on Data with Different Task Correlations
- 对于所有模型,具有较高相关性的数据的效果要优于具有较低相关性的数据的效果;
- 在两个任务相关性搞的情况下,MMoE模型和OMoE模型之间的效果几乎没有区别;但是,当任务之间的相关性降低时,OMoE模型的效果就会明显下降,而对MMoE模型的影响却很小。因此,在低关联性情况下,具有特定于任务的门来建模任务差异至关重要;
- OMoE和MMoE的效果在不同相关度任务的数据中都好于Shared-Bottom。
模型的可训练性(Trainability)对比
模型的可训练性,就是指模型在超参数设置和模型初始化范围内的鲁棒性。
针对数据和模型初始化中的随机性研究模型的鲁棒性,并在每种设置下重复进行多次实验,每次从相同的分布生成数据,但随机种子不同,并且模型也分别初始化,绘制了重复运行的最终损失值的直方图:
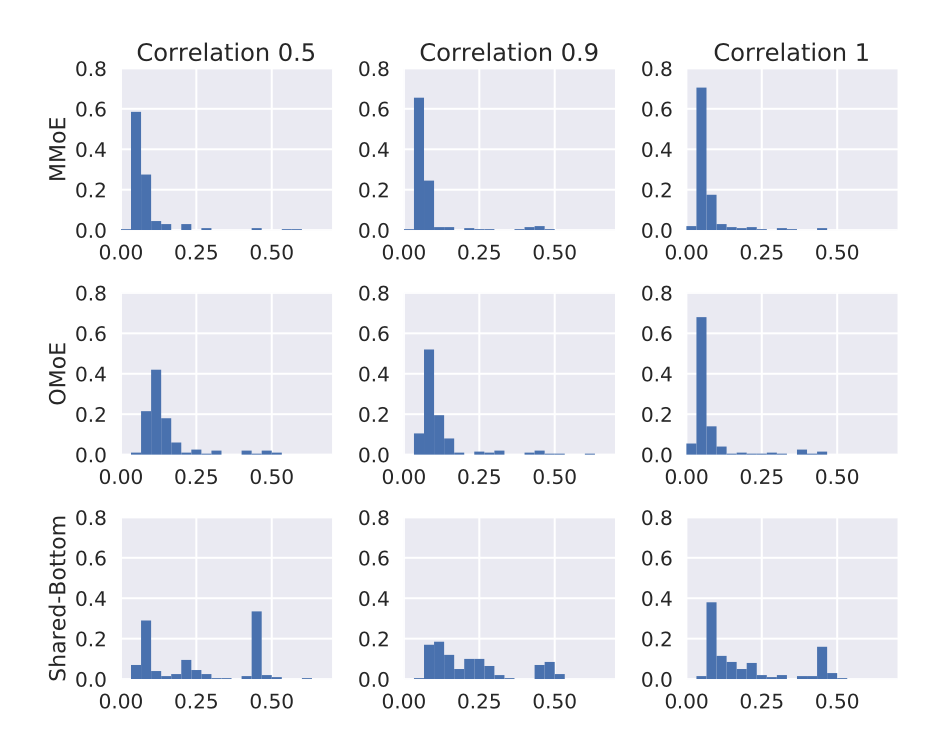
结论:
- 首先,在所有任务相关性设置中,Shared-Bottom模型的性能差异远大于基于MoE的模型的性能差异。这意味着,与基于MoE的模型相比,Shared-Bottom模型通常具有质量较差的局部最小值。
- 其次,虽然任务相关性为1时OMoE模型的性能方差与MMoE模型相似,但当任务相关性降低到0.5时,OMoE的鲁棒性却明显下降。这验证了multi-gate结构在解决由任务差异引起的冲突而导致的不良局部最小值方面的有用性。
- 最后,这三个模型中的最低loss是可比的。具有足够的模型容量,应该存在一个“正确”的 Shared-Bottom模型,该模型可以很好地学习这两个任务。
整体来看,这篇文章是对多任务学习的一个扩展,通过门控网络的机制来平衡多任务的做法在真实业务场景中具有借鉴意义。
参考文献
[1]Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
[2]Adaptive Mixtures of Local Experts/Jacobs, Robert A/Neural Computation 3.1(1991):79-87
[3]Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
[4]MMoE论文笔记/Xindi Lu/cnblog
[5]详解谷歌之多任务学习模型MMoE(KDD 2018)/yymWater/知乎
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!