多任务学习(Multi-Task Learning)
多目标优化背景
推荐系统中,评价一个推荐系统的好坏,需要综合考虑推荐的用户满意度、预测准确度、覆盖率、多样性、新颖性、惊喜度、实时性、信任度以及健壮性等指标。在电商的场景中,我们希望提高用户对推荐结果的点击、停留时间、加入购物车、收藏、购买以及重复购买等指标;在信息流场景,我们希望提高用户点击率的基础上,提高用户关注,点赞、评论等行为,进而提高留存。
广告系统中,CPA广告不仅仅需要用户点击广告,还需要用户点击广告后,下载APP或者产生购买行为才行,所以需要同时优化点击率和点击转化率。如果仅仅优化点击率,那么可能都是一些创意很吸引人甚至三俗的广告被投放,真正优质的广告无法获得展示机会;如果仅仅优化曝光到转化,那么中间过程中的点击信息就没有利用起来,转化数据本身稀疏,训练难度很大,无法达到很好的模型效果。
搜索系统中,同样会遇到用户点击和用户转化行为之间的权衡,单目标的点击率优化比较高的点之后,很容易导致其他后续行为的下降,这说明仅仅是因为标题、创意上吸引了用户,内容并不是用户真正需要的。
在工业界真实的推荐/广告/搜索场景中,我们希望同时优化多个业务目标。
多目标优化解决方案
目前主要使用的策略包括:
- 多模型融合
- 样本权重
- 排序学习
- 多任务学习
解决方案1:多模型加权融合
多模型融合的思路是比较直接的,对于多个优化目标,分别对每一个目标建立一个模型,然后根据自身的业务特点,通过某种方式将这些模型的打分综合起来,计算一个总的分数在进行排序,综合分数的计算通常会根据不同的目标的重要性设定相应的权重来进行调节。
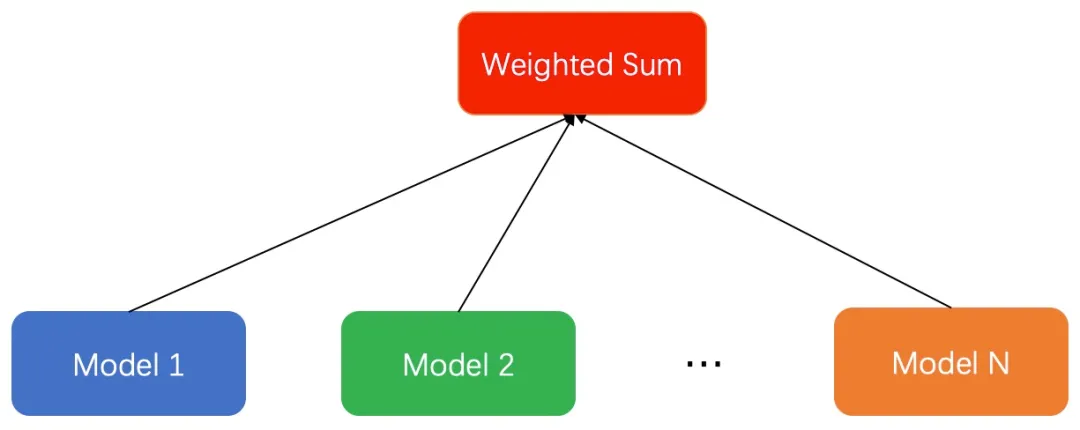
最常见的融合方式就是加权求和: ,
不同的模型得到预测的score之后,通过一个函数将多个目标融合在一起。公式不一定是求和的形式,比如在广告排序中,可以是用调整以后相乘方式进行融合。
优点
- 模型简单。更容易定义问题的正负样本,效果评估也更容易。
- 单一目标上效果更好。一个模型只需要对单一的目标进行建模,在样本充足的情况下,可以将单个目标的优化进行的更加彻底,获得更好的效果。
缺点
- 线上推理部分需要有额外的时间开销,通常我们采用并行的方式请求两个模型进行融合。
- 多个模型之间相互独立,不能互相利用各自训练的部分作为先验,容易过拟合。
- 部分目标数据稀疏,模型准确率低,比如点击转化率样本数据就很稀疏。
- 融合分数的超参难以学习。
解决方案2:样本权重
因为分开训练模型的成本高,融合困难等等问题,很自然的会想到建模的时候把多个目标的样本放到一起训练。对于CPA广告,我们希望的是用户最终的转化,,即在广告曝光(impression)的时候的时候预测用户是否会发生转化(conversion),那么我们定义正样本为曝光并且转化,负样本为曝光没有转化,如果直接这么建模,中间一个很重要的环节,点击就没有办法考虑进去,而真正的转化是很少的,等于我们会丢弃大量的信息。
调节样本权重就是想要把点击利用起来,我们定义曝光并且点击或者转化都为正样本,但是设置不同的样本权重,比如给曝光并且转化的样本设置权重为1,设置曝光并且点击的样本权重为0.2,这个权重可以参考真实的点击到转化比例进行设置。模型训练在计算梯更新参数时,梯度会乘以权重,对样本权重大的样本会给予更大的权重,模型会更加偏向于把样本权重大的样本分对,并且兼顾了两个目标,从而实现多目标的优化。样本权重并不是多目标的建模,而是将不同的目标折算成一个目标。
样本权重调节也有一种简单的变种方案,就是直接按照比例进行样本拷贝,实际效果差不多。
优点
- 模型简单,仅仅需要在模型优化的过程中,梯度更新考虑样本权重即可实现。
- 兼容线上框架,离线处理即可,线上推理部分跟没有使用样本权重的模型一样。
缺点
- 样本权重确定困难,基本都是算法工程师根据业务情况,拍脑袋定的值,上线后需要不断的比例测试。
- 从原理上无法达到最优。
解决方案3:排序学习
推荐/广告/搜索的场景中,我们使用每一次展示和隐式反馈对样本进行模型训练,其实并不需要真正的打分,根本目的是获得相对之间的顺序,因此我们可以使用排序学习来解决多目标问题。
排序学习来解决多目标问题,样本构造会非常的容易,一种常见的标注方法是对多目标产生的物品构建 Pair,比如用户对物品产生的购买,对物品产生了点击,假定我们觉得购买的目标比点击的目标更重要,就可以让,其他目标以此类推。有了顺序对后,我们便可以训练排序学习模型,这样一个模型便可以融合多个目标,而不用训练多个模型。
优点
- 优化了目标排序,不需要设计复杂的超参数,能取得比排序好的效果。
- 本身就是单个模型有多个目标,线下好训练,线上服务压力小。
缺点
- 有些相对顺序不好构造,训练样本中没有的关系,在预测时可能存在。
- 样本数量增大,训练速度变慢,需要构造的情况多。
- 样本的不平衡性会被放大。举例:有的用户有十次点击,有的只有一次,在构造的时候十次的会构造更多的样本,一次的就吃亏。
解决方案4:多任务学习
多任务学习是机器学习的一个子领域,旨在利用不同任务之间的相似性,同时解决多个不同任务。 这可以提高学习效率,还可以充当正则化器。
因为机器学习以及深度学习的成功主要归功于模型能更好的获取数据表达,能从数据中挖掘出需要的信息,而多任务表达学习能从数据中获取更加综合的、更加可变化的信息。单任务模型提取出的特征只针对该单任务有效,单个特征并不能很好地描述一个样本。当任务量较大,并且要求学习到的特征为每一个任务服务,即要求特征有一定的通用性时,多任务学习就更加合适。
多任务学习属于迁移学习的一种,通过共享参数,学习出多个分数,最后结合起来。我们将多任务学习视为一种归约迁移(inductive transfer)。归约迁移(inductive transfer)通过引入归约偏置(inductive bias)来改进模型,使得模型更倾向于某些假设。举例来说,常见的一种归约偏置(Inductive bias)是L1正则化,它使得模型更偏向于那些稀疏的解。在多任务学习场景中,归约偏置(Inductive bias)是由辅助任务来提供的,这会导致模型更倾向于那些可以同时解释多个任务的解。
多任务学习
现在大多数机器学习任务都是单任务学习。对于复杂的问题,也可以分解为简单且相互独立的子问题来单独解决,然后再合并结果,得到最初复杂问题的结果。这样做看似合理,其实是不正确的,因为现实世界中很多问题不能分解为一个一个独立的子问题,即使可以分解,各个子问题之间也是相互关联的,通过一些共享因素或共享表示(share representation)联系在一起。把现实问题当做一个个独立的单任务处理,忽略了问题之间所富含的丰富的关联信息。多任务学习就是为了解决这个问题而诞生的。把多个相关(related)的任务(task)放在一起学习。这样做真的有效吗?答案是肯定的。多个任务之间共享一些因素,它们可以在学习过程中,共享它们所学到的信息,这是单任务学习所具备的。相关联的多任务学习比单任务学习能去的更好的泛化(generalization)效果。
多任务学习的定义
如果有n个任务(传统的深度学习方法旨在使用一种特定模型仅解决一项任务),而这n个任务或它们的一个子集彼此相关但不完全相同,则称为多任务学习(MTL) 通过使用所有n个任务中包含的知识,将有助于改善特定模型的学习。
单任务学习 VS 多任务学习
单任务学习:一次只学习一个任务(task),大部分的机器学习任务都属于单任务学习。
多任务学习:把多个相关(related)的任务放在一起学习,同时学习多个任务。
单任务与多任务对比如图所示:
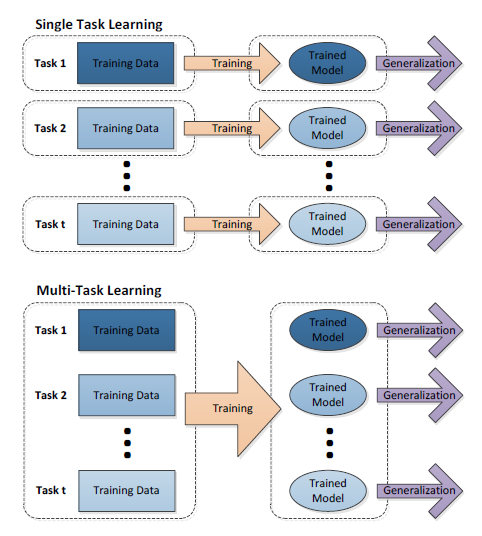
从图中可以发现,单任务学习时,各个任务之间的模型空间(Trained Model)是相互独立的。多任务学习时,多个任务之间的模型空间(Trained Model)是共享的。
假设用含一个隐含层的神经网络来表示学习一个任务,单任务学习和多任务学习可以表示如图所示:
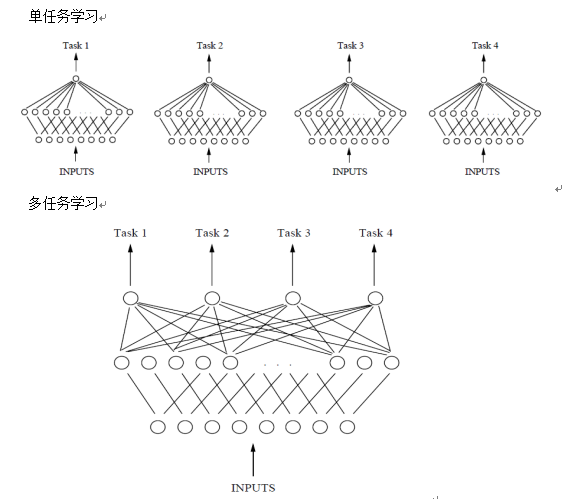
从图中可以发现,单任务学习时,各个task任务的学习是相互独立的,多任务学习时,多个任务之间的浅层表示共享(shared representation)。
多任务学习和其他学习算法的关系
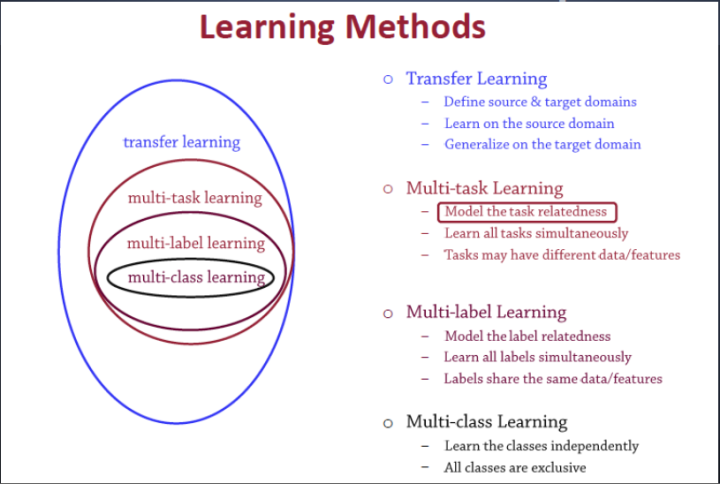
transfer learning:定义一个源域一个目标域,从源域学习,然后把学习的知识信息迁移到目标域中,从而提升目标域的泛化效果。迁移学习一个非常经典的案例就是图像处理中的风格迁移。
multi-task:训练模型的时候目标是多个相关目标共享一个表征,比如人的特征学习,一个人,既可以从年轻人和老人这方面分类,也可以从男人女人这方面分类,这两个目标联合起来学习人的特征模型,可以学习出来一个共同特征,适用于这两种分类结果,这就是多任务学习。
multi-label:打多个标签,或者说进行多种分类,还是拿人举例啊,一个人,他可以被打上标签{青年,男性,画家}这些标签。如果还有一个人他也是青年男性,但不是画家,那就只能打上标签{青年,男性}。它和多任务学习不一样,它的目标不是学习出一个共同的表示,而是多标签。
multi-class:多分类问题,可选类别有多个但是结果只能分到一类中,比如一个人他是孩子、少年、中年人还是老人。
多任务学习的模式
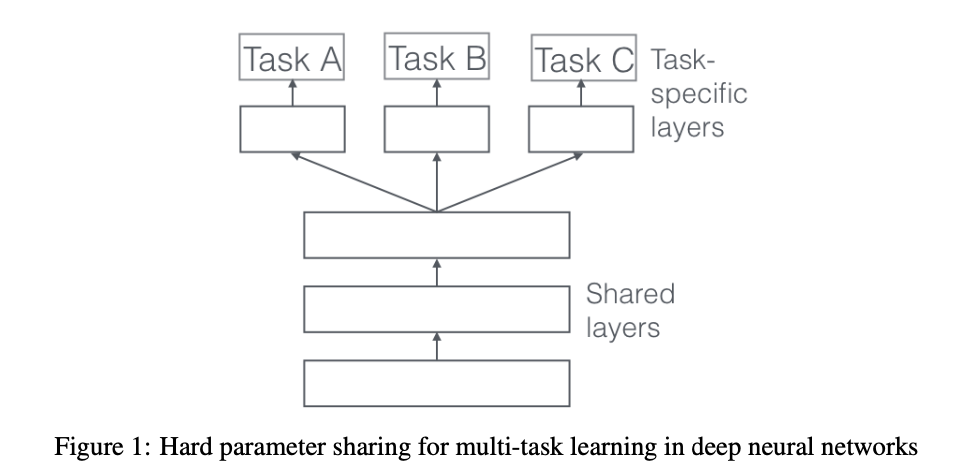
隐层参数的硬共享机制:在所有任务之间共享隐藏层,同时保留几个特定任务的输出层来实现。降低了过拟合的风险。直观来讲,越多任务同时学习,我们的模型就能捕捉到越多任务的同一个表示,从而导致在我们原始任务上的过拟合风险越小。
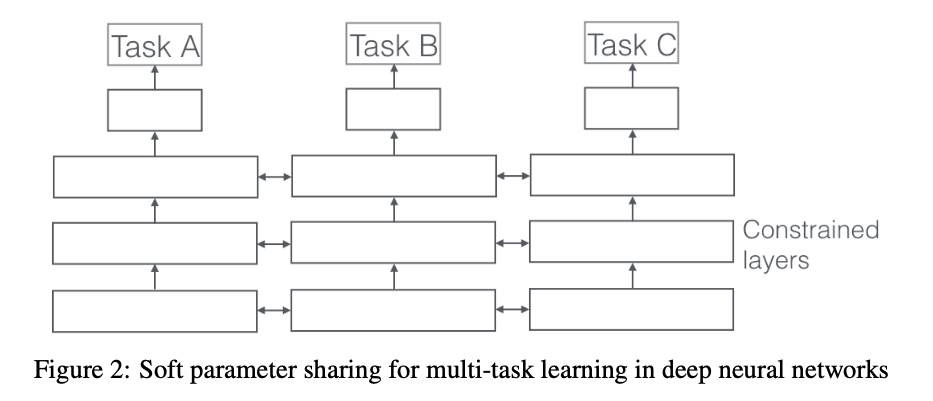
隐层参数的软共享机制:每个任务都有自己的模型,自己的参数。模型参数之间的距离是正则化的,以便鼓励参数相似化。
多任务学习的有效性
隐式数据增加机制:多任务学习有效的增加了训练实例的数目。由于所有任务都或多或少存在一些噪音,例如,当我们训练任务A上的模型时,我们的目标在于得到任务A的一个好的表示,而忽略了数据相关的噪音以及泛化性能。由于不同的任务有不同的噪音模式,同时学习到两个任务可以得到一个更为泛化的表示。如果只学习任务A要承担对任务A过拟合的风险,然而同时学习任务A与任务B对噪音模式进行平均,可以使得模型获得更好表示。
注意力机制:如果一个任务非常嘈杂或数据量有限并且高维,模型可能难以区分相关与不相关的特征。MTL可以帮助模型将注意力集中在重要的特征上,因为其它任务将为这些特征的相关性或不相关性提供额外的证据。
窃听(eavesdroping)或者提示(hint):某特征G很容易被任务B学习,但是难以被另一个任务A学习。这可能是因为A以更复杂的方式与特征进行交互,或者因为其它特征阻碍了模型学习G的能力。通过MTL,我们可以允许模型 “窃听”,即通过任务B学习G。最简单的方法是通过 “提示”,即直接训练模型来预测最重要的特征。
表征偏置:MTL任务偏好其它任务也偏好的表征,这造成模型偏差。这将有助于模型在将来泛化到新任务,因为在足够数量的训练任务上表现很好的假设空间也将很好地用于学习具有相同环境的新任务。
正则化:MTL通过引入归纳偏置作为正则化项。因此,它降低了过拟合的风险以及模型的 Rademacher 复杂度(即适合随机噪声的能力)。
多任务学习的工程实现范式
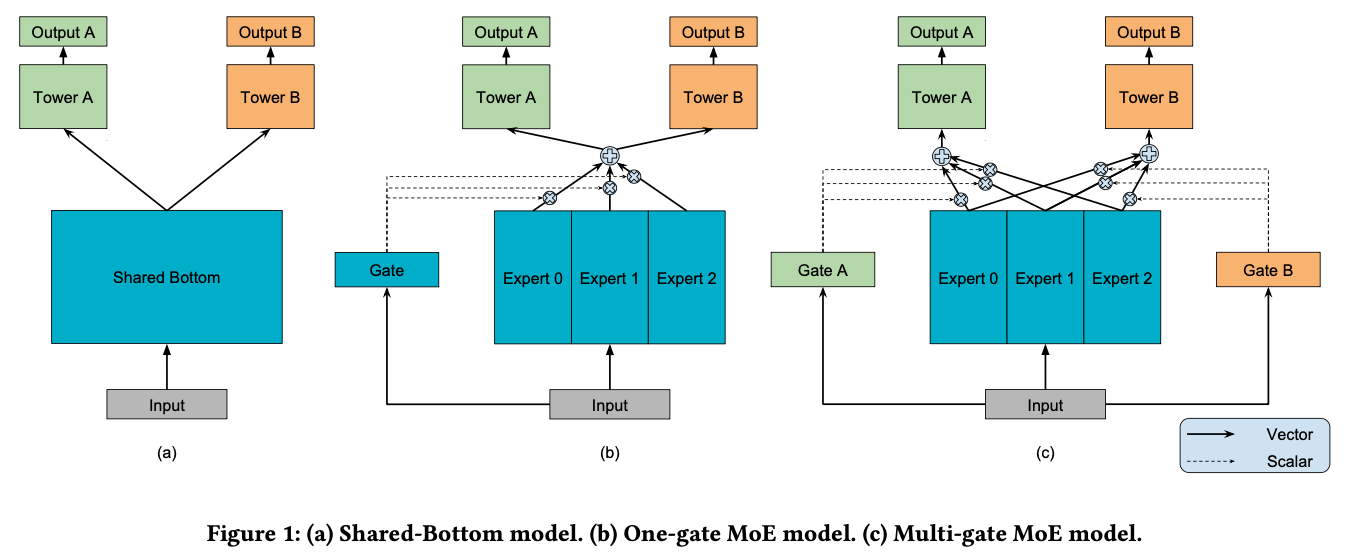
Shared-Bottom model:多任务的学习的本质在于共享表示层,并使得任务之间相互影响,在预测的目标之间的相关性比较高的情况下(比如:猫分类和狗分类,他们通常会有比较接近的底层特征,比如皮毛、颜色等等),这样参数共享层不会带来太大的损失,参数共享层能够加强参数共享,多个目标的模型可以联合训练,减小模型的参数规模,防止模型过拟合。
Multi-gate MoE model:底层特征共享方式的一大特点是在任务之间都比较相似或者相关性比较大的场景下能带来很好的效果,归纳偏置的作用也能够很好的发挥出来,而对于任务间差异比较大的场景,这种共享结构就有点捉襟见肘了。MMoE为每一个模型目标设置一个gate,所有的目标共享多个expert,每个expert通常是数层规模比较小的全连接层。gate用来选择每个expert的信号占比。每个expert都有其擅长的预测方向,最后共同作用于上面的多个目标。
参考文献
[1]推荐系统中如何做多目标优化/SunSuc/知乎
[2]推荐系统中的多任务学习/卢明冬/Blog
[3]模型汇总-14 多任务学习-Multitask Learning概述/深度学习于NLP/知乎
[4]Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!